2. Réseaux et Infrastructure
2.1 Objectifs de ce chapitre
- Connaître les différents composants matériels d’un réseau et leur rôle
- Comprendre quels éléments sont utilisés lors de l’envoi d’une requête réseau HTTP/HTTPS
- Savoir manipuler les différentes commandes de base liées au réseau
- Découper un réseau d’entreprise en sous-réseaux
2.2 Introduction
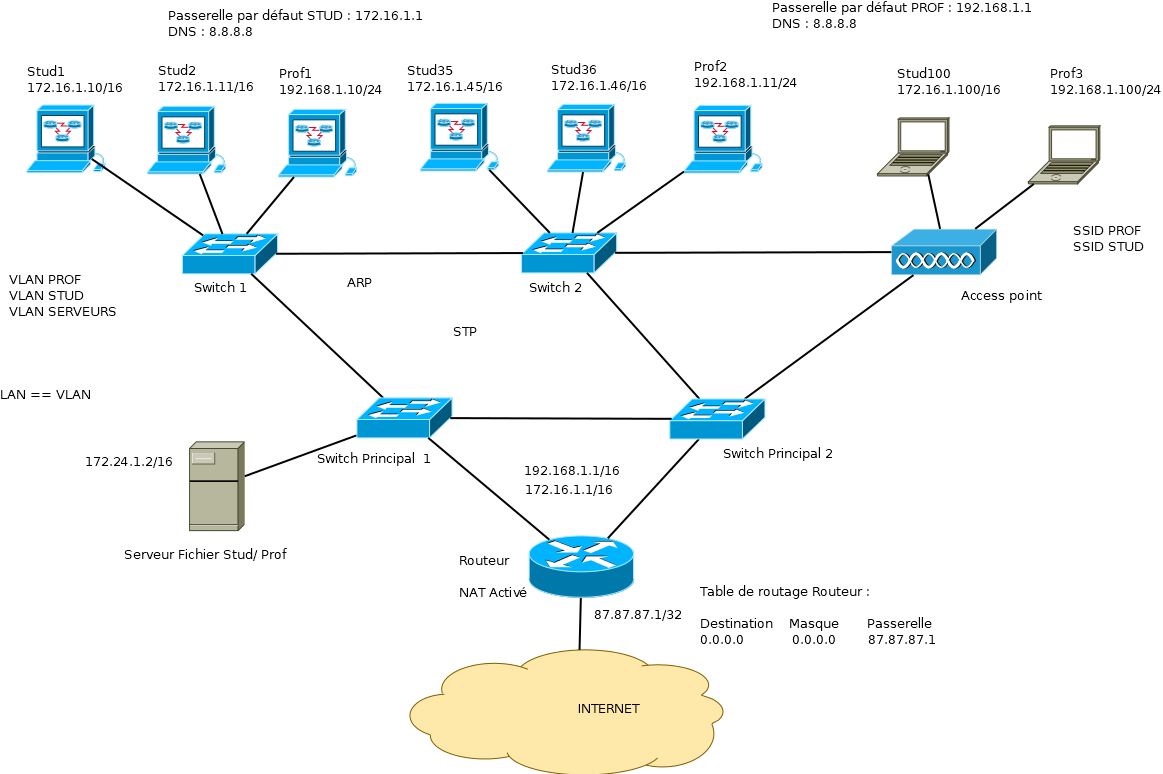
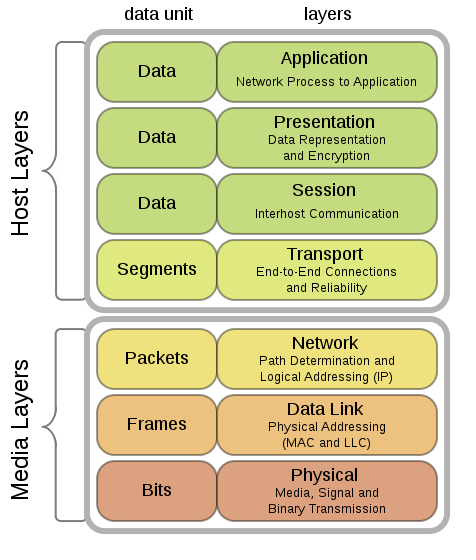
2.3 Couche 1 : Matériel
implémentation majoritaire : l’utilisation d’un réseau avec une topologie en étoile et des câbles Ethernet.
2.4 Couche 2 : Liaison de données
L’identifiant d’une machine est la MAC address. Le composant principal de cette couche (switch) conserve une table des MAC address permettant d’associer chaque port du switch à une MAC address.
2.4.1 VLAN
Les VLAN (Virtual Local Area Network) permettent de séparer certains ports d’un switch par rapport à d’autres. Les ports se verront attribué un numéro de VLAN et les ports ayant un même numéro de VLAN pourront uniquement communiquer entre eux.
L’intérêt des VLAN est multiple :
- Sécurité : séparation des sous-réseaux
- Économique : on peut utiliser au maximum les ports disponibles sur les switchs (on achètera moins de switch et des plus gros)
- Bande passante : optimisation de la bande passante en réduisant la taille des domaines de diffusion (broadcast)
- Facilité de gestion : on peut facilement changer le numéro de VLAN d’un port et donc faire basculer une machine cliente d’un sous-réseau à un autre
2.4.2 STP
le protocole STP (Spanning Tree Protocol), il va autoriser à créer des boucles en désactivant logiquement certains liens et en les réactivant en cas de panne.
2.5 Couche 3 : Réseau
La couche réseau est implémentée dans une infrastructure par des routeurs. Ceux-ci feront transiter des paquets IP d’un réseau à un autre. L’identifiant d’une machine pour cette couche est une adresse IP. Une adresse IP est composée d’une adresse réseau et d’un masque. Le masque d’une adresse IP est noté soit sous le format A.B.C.D (Ex: 255.255.0.0) ou sous le format CIDR (Ex : /16).
2.5.1 Adresses spéciales
| Plage | Usage |
|---|---|
| 127.0.0.0/8 | Boucle locale |
| 10.0.0.0/8 | Adresses privées |
| 172.16.0.0/12 | Adresses privées |
| 192.168.0.0/16 | Adresses privées |
| 224.0.0.0/4 | Multicast |
Les adresses privées sont réservées pour être utilisées dans les réseaux d’entreprises (LAN) et ne sont pas routables sur Internet (Voir NAT).
2.5.3 Commandes réseau
| Linux | Windows | Explication |
|---|---|---|
| ifconfig OU ip addr | ipconfig | Configuration / Consultation des informations IP d’une machine |
| route | route | Configuration / Consultation des informations de routage d’une machine |
| ping | ping | Tester la connectivité IP d’une machine |
| traceroute | tracert | Voir le chemin parcouru par un paquet IP |
2.5.4 ARP
Il permet à une machine de demander l’adresse MAC d’une autre machine sur base de son adresse IP.
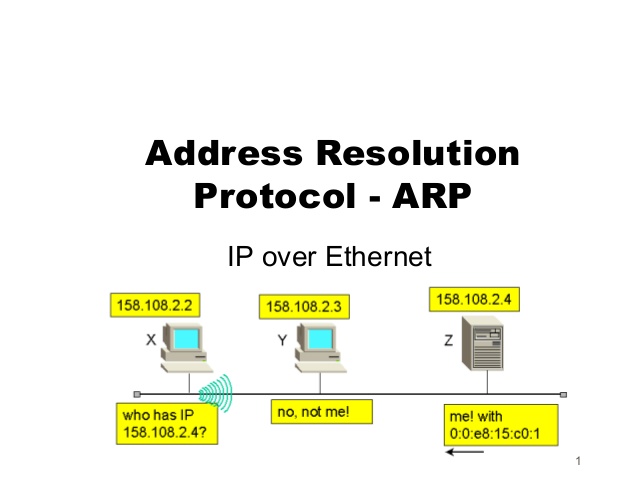
D’un point de vue sécurité, le protocole ARP est sensible aux attaques de type ARP cache poisoning/spoofing. Il s’agit pour l’attaquant de répondre à toutes les requêtes ARP en vue de détourner le trafic du sous-réseau vers sa propre machine et d’effectuer des écoutes.
2.5.5 Découpage en sous-réseaux
Vous devez être capable de découper un réseau en sous-réseaux. Ceci peut être demandé dans la partie pratique de l’examen.
2.5.6 Table de routage
Le composant principal de cette couche 3, le routeur, maintient une table de routage. Une table de routage est un tableau qui précise pour une destination d’un sous-réseau (adresse réseau + masque) une passerelle (adresse IP d’une machine/routeur).
2.5.7 Passerelle par défaut
chaque machine possédera une passerelle par défaut (0.0.0.0/.0.0.0.0). Celle-ci sera utilisée lorsqu’aucune règle plus précise ne pourra être utilisée dans la table de routage. Grâce à cette passerelle par défaut, il est également plus simple d’automatiser la connexion de machines clientes à son réseau. En effet, il suffira de fournir à chaque machine cliente une adresse IP, un masque et une passerelle par défaut et celle-ci pourra utiliser notre réseau. Cette automatisation pourra se faire via un serveur DHCP.
2.5.8 Routage IP
Une machine a toujours accès au(x) réseau(x) auquel(s) elle est connectée directement.
2.6 Couche 4 : Transport
Une application sera donc identifiée via son port.
| Application | Port réservé |
|---|---|
| Web (HTTP) | 80 |
| SSH | 22 |
| HTTPS | 443 |
| DNS | 53 |
Une politique de sécurité de base pour les administrateurs système est donc de bloquer sur le serveur tous les ports hormis ceux des applications utilisées.
3 Services réseaux (DHCP-DNS-NAT)
3.1 Objectifs de ce chapitre
- Savoir expliquer le rôle des 3 services réseaux de base
3.2 Introduction
Pour qu’un réseau d’entreprise fonctionne correctement, il est nécessaire d’avoir au minimum 3 services à savoir :
- DNS (Domain Name System)
- DHCP (Dynamic Host Configuration Protocol)
- NAT (Network Address Translation)
3.3 DNS
Pour rappel, le système DNS permet de traduire un nom de domaine en une adresse IP et inversement.
dans un réseau d’entreprise, les machines clientes porteront des noms et ces noms devront être traduits en une adresse IP.
En tout cas, l’administrateur système de l’entreprise devra gérer les enregistrements DNS de l’entreprise notamment les enregistrements DNS pointant vers les serveurs de l’entreprise et qui devront être accessibles depuis l’extérieur.
Un administrateur système installera généralement 2 serveurs DNS. Cette redondance permettra de gérer plus facilement la défaillance d’un serveur.
3.3.1 Configuration DNS
Une zone DNS contient différents types d’enregistrements :
- SOA : Start of Authority (informations générales sur la zone DNS)
- A : Enregistrement d’un hôte (correspondance Nom → IP)
- CNAME : Alias
- PTR : Enregistrement d’une IP (correspondance IP → Nom)
- MX : Mail server (adresse IP du serveur mail de la zone)
- NS : Name Server (serveur DNS pour la zone)
3.3.2 Résolution d’un nom
Il est très important de ne pas oublier que toute résolution de noms sur une machine commence par l’inspection du fichier hosts. Ce fichier est présent sous Linux à cet endroit /etc/hosts et sous Windows à cet endroit c:\Windows\System32\Drivers\etc\hosts.
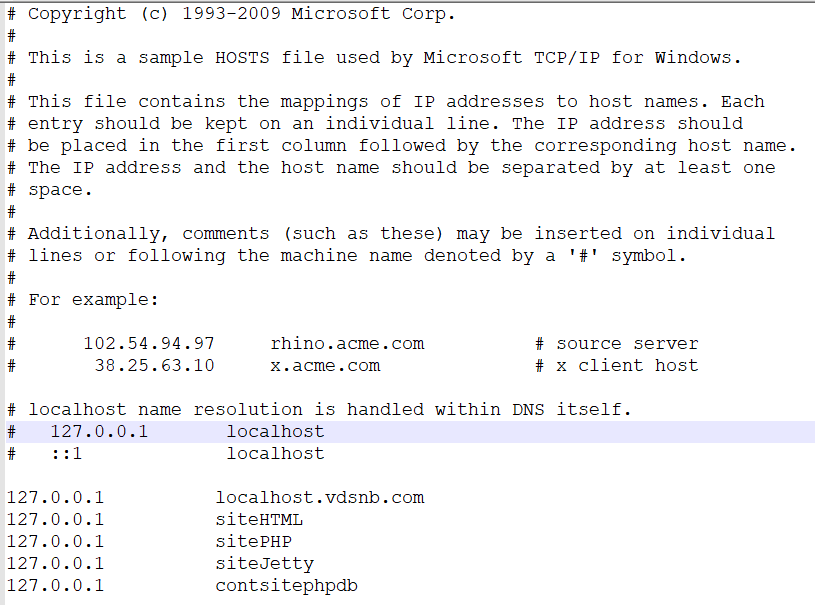 Les administrateurs système utilisent abondamment ce fichier pour tester des services car cela évite l’installation d’un serveur DNS. En production, un serveur DNS sera bien évidemment employé.
Les administrateurs système utilisent abondamment ce fichier pour tester des services car cela évite l’installation d’un serveur DNS. En production, un serveur DNS sera bien évidemment employé.
3.4 DHCP
Pour qu’une machine cliente puisse se connecter à un réseau et surfer sur Internet, cette machine a besoin au minimum des informations suivantes :
- se voir attribuer une adresse IP et un masque au sein de ce réseau
- obtenir une passerelle par défaut (pour aller sur Internet notamment)
- obtenir des serveurs DNS (pour traduire les noms en adresse IP)
Un serveur DHCP permettra de répondre à ces besoins de manière automatique.
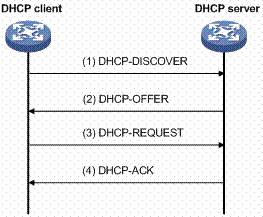
Les informations reçues en provenance du serveur DHCP ne seront valables qu’un certain temps. On parle de bail. Le client pourra évidemment renouveler son bail.
Un administrateur système installera plusieurs serveurs DHCP pour se prémunir de la panne d’un serveur. Deux serveurs DHCP ne pouvant pas distribuer les mêmes adresses IP, l’administrateur système devra répartir ces adresses de manière intelligente entre les 2 serveurs.
3.5 NAT
Le NAT est utilisé abondamment par les réseaux d’entreprise pour traduire les adresses IP privées de clients en adresses publiques routables sur Internet. Pour rappel, les adresses IPv4 sont limitées à 4 milliards ce qui ne permet pas de couvrir la totalité du globe terrestre. Donc certaines plages d’adresses ont été réservées (adresses privées) pour pouvoir être attribuées dans les réseaux locaux des entreprises. Ceci est très bien, mais pour aller sur Internet, j’ai besoin d’une adresse publique, autrement dit d’une adresse routable sur Internet. C’est ici qu’intervient le NAT. Vous allez comprendre comment la terre entière peut surfer sur Internet avec seulement 4 milliards d’adresses disponibles.
3.5.1 Source NAT (SNAT)
Chaque machine cliente sera connectée au réseau de l’entreprise via une adresse privée et recevra une passerelle par défaut qui sera généralement le routeur qui vous permettra d’aller sur Internet. Ce routeur disposera d’une adresse IP publique reçue par votre fournisseur d’accès à Internet et il disposera également d’une adresse privée dans le réseau de l’entreprise. Nous activerons le NAT sur le routeur ce qui aura pour effet de traduire l’adresse IP source de tout paquet IP sortant sur Internet par l’adresse IP publique du routeur.
Le routeur va en fait identifier les machines clientes via un port choisi aléatoirement.
3.5.2 Port forwarding
Le NAT introduit une isolation du réseau de l’entreprise. En effet, il est impossible d’atteindre une machine du réseau de l’entreprise depuis l’extérieur. La seule machine que l’on sait atteindre est le routeur. Ceci est intéressant en termes de sécurité, mais nous devons quelquefois avoir accès à un serveur présent dans le réseau de l’entreprise. Pour ce faire, nous pouvons configurer le NAT pour qu’il fasse du port forwarding.
Le principe est le suivant : pour accéder à un serveur de l’entreprise, on attribue un port sur le routeur dédié à ce serveur. Dès que le routeur reçoit une connexion de l’extérieur sur ce port, il transfère les paquets vers l’adresse privée du serveur.
Le port forwarding est utilisé abondamment dans les réseaux surtout depuis la virtualisation. Par exemple, VirtualBox définit par défaut un réseau NAT entre la machine hôte et la machine virtuelle invitée. Si vous installez un serveur dans la machine virtuelle invitée et que vous voulez y accéder depuis l’extérieur (votre machine hôte ici), vous devrez faire du port forwarding. Ceci n’est pas compliqué, il suffit de faire une association entre un port de la machine hôte et un port la machine virtuelle.
4 Installation Serveurs Linux et Windows
4.1 Objectifs de ce chapitre
- Comprendre les différents éléments qui mérite attention lors de l’installation d’un serveur
4.4 Licences
4.4.1 Logiciel Libre – GPL
GPL (GNU Public Licence).
Cette licence se caractérise par 4 libertés à respecter :
- La liberté d’exécuter le logiciel, pour n’importe quel usage
- La liberté d’étudier le fonctionnement d’un programme et de l’adapter à ses besoins, ce qui passe par l’accès aux codes sources
- La liberté de redistribuer des copies
- L’obligation de faire bénéficier la communauté des versions modifiées (copyleft)
La dernière liberté (le copyleft) est la plus contraignante, car elle nécessite qu’un logiciel utilisant une licence GPL doive être distribué sous licence GPL.
4.4.2 LGPL
La licence LGPL (Lesser GNU Public Licence) reprend les fondements de la licence GPL en supprimant la restriction sur l’hérédité de la licence GPL. Cette licence permet également la cohabitation de plusieurs licences (libres et propriétaires) au sein d’un logiciel. Il s’agit pour ces raisons de la licence préférée des développeurs de librairies.
4.4.5 Remarques
Gratuit ne veut pas dire libre ! La gratuité implique simplement que l’on ne paye pas pour un produit.
Open source ne veut pas dire libre ! L’Open source implique simplement que nous avons la possibilité d’avoir accès au code source.
La notion de logiciel libre fait référence aux 4 libertés citées ci-dessus.
4.5 RAID
Le RAID (Redundant Arrays of Inexpensive Disks) est un mécanisme de redondance de disques. Celui-ci a plusieurs objectifs combinables à savoir se prémunir contre la panne d’un disque et améliorer les performances en écriture sur les disques.
| Niveau | Explication | Avantages | Inconvénients |
|---|---|---|---|
| RAID 0 | Les données sont écrites en parallèle sur plusieurs disques | Gain en performance | Perte d’un disque == perte des données |
| RAID 1 | Les données sont écrites sur des disque en miroir | Tolérance aux pannes disques | Coût -> disque en double |
| RAID 5 | Les données sont écrites en parallèle sur au minimum 3 disques (2 disques de données + 1 disque de parité) | Tolérance aux pannes disques + performance | Minimum de 3 disques requis |
Le RAID 5 s’appuie sur l’opérateur logique XOR. La parité de chaque écriture est calculée via cet opérateur. En cas de perte d’un disque, l’information peut être reconstituée à partir des 2 autres disques toujours via cet opérateur XOR.
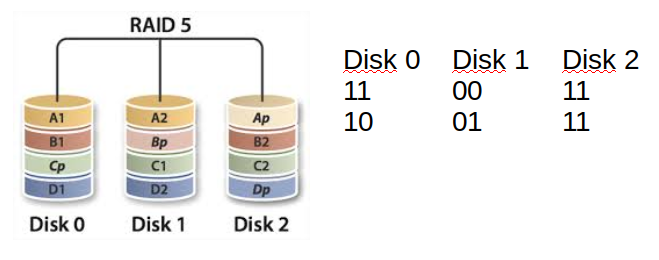
4.6.1 Partitionnement
Le partitionnement désigne l’opération de diviser un disque en partitions. Un partitionnement bien réfléchi facilitera la maintenance des serveurs. Une partition système et une partition “données utilisateur” faciliteront par exemple la mise en place de sauvegardes.
4.6.1.1 LVM
LVM (Logical Volume Manager) est une solution permettant une gestion dynamique du partitionnement disponible sous Linux.
4.6.1.2 Systèmes de fichiers
Voici les principaux :
- Ext2,Ext3,Ext4 : système de fichiers Linux incluant le concept de permissions (Ext4 est actuellement la version la plus utilisée sous Linux)
- NTFS : système de fichiers Windows incluant le concept de permissions (NTFS est actuellement la version la plus utilisée sous Windows)
- FAT32 : ancien système de fichiers limité à des fichiers de maximum 4GB , pas de systèmes de permissions, multiplateforme
- exFAT : remplaçant de FAT32, pas de limitation à 4GB, pas de permissions, multiplateforme
- Swap : partition d’échange (extension de la mémoire RAM sous Linux)
- Btrfs : nouveau système de fichier permettant la prise d’instantanés (snapshot d’une partition) et le redimensionnement de partitions à chaud. Ce système utilise en interne les arbres B-tree.
- tmpfs : système de fichiers temporaire en mémoire vive (RAM), utilisé pour stocker des fichiers temporaires (
/tmp) qui ne nécessitent pas de persistance après un redémarrage.
4.6.1.3 Montage des partitions
Chaque ligne du fstab indique donc une partition, son point de montage, le système de fichiers utilisé, les options, si une sauvegarde doit être faite avec l’utilitaire dump (peu utilisé), l’ordre de vérification des disques lors d’une demande de vérification (fsck).
4.6.1.4 Chiffrement des partitions
Une partition non chiffrée peut être lue facilement sans autorisations particulières via un live-cd si on a un accès physique à une machine.
Linux propose LUKS (Linux Unified Key Setup) qui permet un chiffrement des partitions (à l’installation ou plus tard). Windows propose, quant à lui, BitLocker pour crypter ses partitions.
4.6.2 Amorçage
Lors du démarrage d’une machine, un chargeur d’amorçage (bootloader) est lancé. Celui-ci s’occupera de lancer le système d’exploitation ou de présenter les différents systèmes d’exploitation dans le cas d’un multi-boot. Windows propose winload comme chargeur d’amorçage tandis que Linux propose essentiellement GRUB (GRand Unified Bootloader).
4.7 Installation Windows (Windows Server 2016)
L’installation d’un serveur Windows est assez simple. C’est l’ajout de service, appelé rôle sous Windows, qui reste plus complexe. Les rôles permettent d’installer un Active Directory, un serveur DNS, DHCP, … .
Un aspect important sous Windows est la gestion des licences. Les licences serveur doivent être comptabilisées suivant le nombre de cœurs physiques du processeur. Il faut également comptabiliser les licences d’accès client (CAL).
5 Administration Linux (Debian)
5.1 Objectifs de ce chapitre
- Savoir administrer un serveur Linux (Debian)
5.3 APT
Toutes les distributions Linux disposent d’un système de gestion des packages
L’outil APT dispose d’un fichier de configuration (/etc/apt/sources.list) permettant de renseigner les dépôts à utiliser.
5.3.1 Commandes APT
Mise à jour du dépôt local :
apt-get updateInstaller un logiciel :
apt-get install <paquet1> <paquet2> ... 5.4 SSH
Les systèmes Linux actuels sont le plus souvent gérés en ligne de commande (pas d’interface graphique) et à distance.
5.4.1 Fonctionnement
Nous ne donnerons ici qu’un résumé du fonctionnement du protocole SSH (Secure Socket Shell). Le protocole SSH effectue un échange de clés de chiffrement avant d’utiliser ces dernières pour crypter toutes les communications entre le client et le serveur. Le port 22 est le port par défaut utilisé par SSH.
SSH est un service qui est initialisé/démarré par systemd.
5.4.3 Configuration
Par défaut, SSH est installé pour permettre une authentification par login et mot de passe pour tous les utilisateurs présents sur le serveur (hormis root) ainsi que par clé (root compris).
Nous nous contenterons de ce comportement par défaut pour ce cours.
5.4.4 Utilisation
Le client SSH a besoin des informations suivantes : un nom de machine ou une adresse IP, un login et un mot de passe. On peut remplacer l’authentification par login/mdp par une clé.
5.4.5 Copie de fichiers
Il est à noter que dès que vous avez un accès SSH, vous pouvez copier des fichiers entre votre machine hôte et invitée via SCP/SFTP. Ceci peut se faire en ligne de commande (Linux), avec le logiciel WinSCP (Windows) ou Cyberduck (Mac).
5.4.6 Authentification par clé sur un serveur Linux
Attention si vous utiliser Puttygen → copier le contenu de la clé publique généré dans un fichier texte. N’utiliser pas le bouton « Save public key » car il enregistre la clé sous un format non reconnu sous Linux.
Le fichier de la clé publique est tranféré. Il faudra copier son contenu dans le fichier authorized_keys de l’utilisateur souhaité.
Attention aussi à mettre des droits corrects. Le fichier authorized_keys doit être propriété de l’utilisateur et accessible en lecture uniquement.
5.4.7 Tunnel SSH
La création d’un tunnel SSH permet de connecter 2 machines en encapsulant le trafic de la première et en le redirigeant vers la seconde. Cette technique est souvent appelée le VPN du pauvre car elle permet notamment de donner accès à une machine du réseau local de l’entreprise à des ordinateurs distants et à moindres frais (de configuration).
5.5 Gestion des utilisateurs
5.5.1 adduser-deluser-addgroup-delgroup
Il est à noter que adduser crée un profil pour l’utilisateur basé sur un répertoire squelette situé dans /etc/skel. Tout fichier placé par l’administrateur dans ce répertoire squelette sera copié par défaut dans le répertoire de l’utilisateur lors de l’appel à adduser.
Par défaut, la home directory créée par adduser est accessible uniquement au propriétaire en lecture, écriture et exécution (voir /etc/adduser.conf). Ceci peut être changé dans /etc/adduser.conf au besoin.
5.5.3 SUDO
5.5.3.1 Fonctionnement
Pour qu’un utilisateur puisse exécuter une commande avec « sudo », il doit faire partie du groupe sudo.
5.5.3.4 Avantages de SUDO
Les avantages du SUDO sont les suivants:
- Permettre à des utilisateurs d’exécuter une commande en tant que superutilisateur sans devoir connaître le mot de passe de root.
- Travailler en mode non privilégié et n’utiliser le mode privilégié que quand cela est nécessaire. Ceci réduit le risque de commettre des dommages pour le système.
- Contrôler et enregistrer qui fait quoi (SUDO enregistre toutes le commandes sudo effectuées dans le journal de systemd).
- Renforcer la sécurité. En désactivant le compte root et en le remplaçant par un compte « sudo », un attaquant ne connaîtra pas le mot de passe, ni le nom du compte !
5.6 Passwd
Passwd permet de changer le mot de passe de son compte et de tous les comptes (pour le root).
5.7 SystemD
Les niveaux d’exécution :
- 0 : arrêt (la commande init 0 arrête le système)
- 1 : mono-utilisateur (utiliser par exemple pour la maintenance)
- 3 : multi-utilisateur sans environnement graphique
- 2-4 : idem que 3, mais peut être défini par l’utilisateur (peu utilisé en pratique)
- 5 : multi-utilisateur avec environnement graphique
- 6 : redémarrage (la commande init 6 redémarre le système)
L’objectif principal de SystemD (tout comme SystemV) est de démarrer des services, appelés daemons dans le monde Linux. Il est donc normal que celui-ci propose différentes manières d’implémenter son service.
5.8 Débogage
Voici quelques méthodes et outils courants pour diagnostiquer et résoudre les problèmes sur un serveur Linux :
- Consulter les logs système :
Les fichiers de logs se trouvent généralement dans/var/log/. Les plus importants sont :/var/log/syslogou/var/log/messages: logs système généraux/var/log/auth.log: authentification et sudo/var/log/apache2/error.log: erreurs Apache/var/log/mysql/error.log: erreurs MySQL/MariaDB
- Utiliser les commandes de diagnostic :
journalctl: consulter les logs gérés par systemdsystemctl status <service>: état d’un serviceps aux/top/htop: surveiller les processusdf -h/du -sh: vérifier l’espace disquefree -h: vérifier la mémoirenetstat -tulnp/ss -tulnp: ports ouverts et services écoutantping,traceroute,nslookup: diagnostic réseau
- Redémarrer un service :
systemctl restart <service>
- Vérifier la syntaxe d’un fichier de configuration :
- Par exemple, pour Apache :
apache2ctl configtest - Pour Nginx :
nginx -t
- Par exemple, pour Apache :
- Analyser les permissions :
ls -lpour vérifier les droits sur les fichiers et dossiers
- Utiliser des outils de surveillance :
uptime: charge systèmedmesg: messages du noyau
Bonnes pratiques : - Toujours lire les messages d’erreur affichés par les commandes. - Appliquer les changements un par un et tester à chaque étape. - Documenter les problèmes rencontrés et leurs solutions pour référence future.
En résumé : savoir où chercher les logs, utiliser les commandes de base, et adopter une démarche méthodique sont les clés d’un débogage efficace en administration système.
6 Serveurs Web (Apache)
6.1 Objectifs du chapitre
- Déployer un site Web via Apache
6.3 Etapes de déploiement d’un site Web
- Installer le paquet du serveur Web (Apache)
- Transférer/Installer le code du site Web sur le serveur (/var/www)
- Créer un VirtualHost
- Activer le site
- Faire correspondre la Directive ServerName et /etc/hosts
- Tester le site Web en local
6.5 Caractéristiques d’Apache
Apache étant hautement configurable, il se caractérise par une configuration morcelée.
Ce fichier inclut tout simplement d’autres fichiers et répertoires à savoir:
- /etc/apache2/sites-available : définitions de sites Web (VirtualHost)
- /etc/apache2/sites-enabled : définitions de sites Web (VirtualHost) activés
- /etc/apache2/mods-available : liste des modules (SSL, proxy, ..) installés
- /etc/apache2/mods-enabled : liste des modules (SSL, proxy, ..) activés
- /etc/apache2/conf-available : liste des configurations (charset, ..) disponibles
- /etc/apache2/conf-enabled : liste des configurations (charset, …) activées
- /etc/init.d/apache2 : un service qui sera démarré/arrêté par SystemD
- /etc/apache2/ports.conf : la configuration des ports pour apache (80 et 443 par défaut)
6.6 VirtualHost
Les virtualhosts permettent de déployer plusieurs sites Web sur un même serveur (même adresse IP). La distinction se fait en général sur le nom du site, apache doit en effet savoir suivant l’URL quel site il doit présenter.
Ensuite, il faut activer le site comme suit :
#activer un site
#commande à entrer dans /etc/apache2/sites-available
a2ensite monsite.conf6.7 Reverse proxy
Un proxy inverse est un serveur frontal c’est-à-dire un serveur exposé sur Internet et par lequel toutes les requêtes passeront. Ce serveur ne traitera pas les requêtes, mais se contentera de les rediriger vers d’autres serveurs internes à l’entreprise.
Les intérêts de ce mécanisme sont multiples. Vu qu’il n’y a qu’un seul point d’accès, la sécurité est plus facile à gérer. Cela permet également de mettre en œuvre du «load balancing» entre des serveurs internes. C’est également un moyen simple de rendre disponible un serveur interne sur le Web (pas besoin de configuration réseau).
6.9 Apache et HTTPS
Le port par défaut pour les communications https est le 443.
6.9.3 Let’s Encrypt
Let’s encrypt est une autorité de certification libre, gratuite et automatisée. Ceci permet d’obtenir un certificat valide pour son site Web sans trop d’effort.
7 Partage et accès réseau
7.1 Objectifs du chapitre
- Connaître les différents moyens de partage et d’accès à un serveur et leur rôle
7.2 NFS
NFS est un protocole réseau couramment employé pour partager des fichiers sur un réseau. NFS fonctionne en mode client-serveur. NFS est un protocole performant, mais sans sécurité accrue. Ce protocole est le protocole de partage réseau par excellence sous Linux/MacOS.
7.2.3 Fonctionnement NFS
NFS vérifie l’identité des utilisateurs via les UID, GID. Il faut donc que les UID, GID de la machine distante et locale corresponde. L’UID de root est toujours le même (0).
Il est donc important de comprendre que NFS (v2,V3) ne demande pas aux utilisateurs de s’authentifier.
7.3 SAMBA
SMB/CIFS est un protocole propriétaire utilisé sous Windows pour les partages réseau.
Vous connaissez certainement ces partages réseaux qui ont des paths UNC de la forme : \machineserveur\partage.
Il permet donc une interopérabilité entre les 2 mondes (Linux/Windows) notamment:
- Créer des partages sous Linux accessible sous Windows
- Transformer un serveur Linux en Domain Controler
- Authentifier des clients Linux sur un Active Directory
Samba fonctionne tout comme NFS en mode client-serveur. Samba possède une gestion plus élaborée au niveau de l’authentification et des droits des utilisateurs par rapport à NFS.
7.4 VPN
Un VPN (Virtual Private Network) est un système permettant de relier 2 réseaux via un réseau non sûr tout en garantissant un trafic sécurisé (crypté) et de manière transparente. On parle de tunnel.
7.4.1 Classification VPN
Il existe différents types de VPN à savoir:
- LAN to LAN / Site to Site permettant de relier 2 réseaux ( Ex: relier des succursales d’une entreprise éparpillées dans le monde)
- RoadWarrior permettant à un PC externe de se connecter à l’entreprise (Nomadisme des employés)
Il est important de comprendre que le VPN crée un réseau et le configure pour que le réseau distant (LAN to LAN) ou PC distant (Road Warrior) soit considéré comme s’il était dans l’entreprise. L’utilisateur pourra donc utiliser tout ce qui accessible dans le LAN de l’entreprise (imprimantes … ).
7.4.3 Protocoles VPN
| Protocole | Couche Réseau | Remarques |
|---|---|---|
| OpenVPN | Couche Application | OpenVPN est un logiciel créant un VPN en se basant sur SSL/TLS – RoadWarrior ou Site to Site |
7.5 FTP
Le FTP (File Transfer Protocol) est un protocole réseau standard. Le protocole FTP utilise un canal pour le transfert des données et un autre pour le contrôle. C’est pourquoi il utilise par défaut 2 ports ( 20→ données, 21 → contrôle). Le canal de contrôle permet d’envoyer les commandes FTP ( put, get, open, close, ls, …).
Il peut être sécurisé via SSL/TLS (FTPS) ou par SSH (SFTP). Regardez dans WinSCP, vous verrez que vous transférez par défaut vos fichiers par SFTP!
7.5.1 Modes
Le protocole FTP peut s’utiliser en mode actif ou passif.
Dans le mode actif, le client peut choisir son port de connexion pour la réception des données. Le serveur initialisera une connexion de son port 20 vers le port choisi par le client. Le client doit donc accepter les connexions entrantes sur le port choisi. Ceci pose souvent problème car les clients se trouvent généralement dans un LAN qui effectue du NAT vers l’extérieur. C’est pourquoi le mode actif est le moins utilisé.
Dans le mode passif, le serveur impose le port de connexion pour le transfert des données. Le port choisi par le serveur est envoyé au client qui initialise alors la connexion.
7.6 Terminal Server
Le Terminal Server repose sur le protocole RDP (Remote Desktop Protocol) développé par Microsoft.
Terminal Server permet non seulement la prise à distance d’un serveur avec son interface graphique, mais aussi de monter des lecteurs locaux sur le serveur distant.
8 Annuaires et Authentification
8.1 Objectifs du chapitre
- Connaître les différents composants d’un Active Directory et leurs rôles
Le protocole LDAP (Lightweight Directory Access Protocol) a été défini pour permettre d’interroger et de modifier un annuaire. Il est depuis devenu une référence et un standard pour l’authentification.
LDAP est en fait devenu bien plus qu’un protocole, c’est une norme qui définit:
- un protocole: comment sont échangées les données
- un modèle de nommage: comment sont nommées les entrées dans l’annuaire
- un modèle fonctionnel: quelles sont les méthodes pour accéder aux données
- un modèle d’information: nature et description des données
- un modèle de sécurité: description de la sécurité des données (quel chiffrement …)
- Réplication: comment répliquer des données entre serveurs LDAP pour se prémunir des pannes? Ce point n’est pas encore standardisé.
OpenLDAP est la solution reconnue du monde libre (paquet slapd dans Debian). La solution Active Directory de Microsoft est sans doute la plus connue et répandue.
8.2 Modèle de nommage
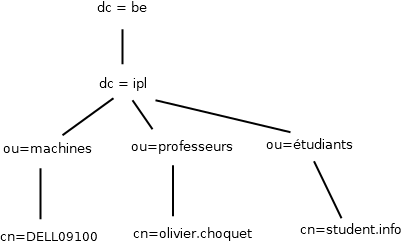
Voici le vocabulaire de base utilisé dans un annuaire LDAP:
- DC : Domain Component. Racine de l’arbre
- DN : Distinguished Name. Chemin complet vers un élément (Les DN sont uniques)
- OU : Organizational Unit. Division de l’entreprise rassemblant des CN.
- CN : Common Name. Nom d’un élément
Exemple :
8.3 Modèle fonctionnel
LDAP a défini différentes méthodes permettant de modifier et consulter l’annuaire. Voici la liste des principales méthodes :
- Bind : s’authentifier auprès du serveur LDAP. Ceci est nécessaire avant de demander au serveur une opération au serveur
- Add/Modify/Delete : mise à jour de l’annuaire.
- Search : «search» permettra de rechercher un élément ou plusieurs éléments dans l’annuaire en précisant une base, une portée et éventuellement des filtres (voir ci-dessous).
- Compare : vérifie qu’un élément contient ou non un attribut
- Unbind : se déconnecter du serveur
8.4 Modèle d’informations
LDAP définit le modèle d’information suivant :
- Entrée: composé d’attributs, possède un type (classe d’objets)
- Schéma: définition des attributs possibles et classes d’objets
- DN (Distinguished Name)
8.5 Modèle de sécurité
Le transport des messages LDAP sera chiffré via SSL/TLS. L’utilisateur, une fois authentifié (via un bind), aura accès aux données suivant les règles établies dans les ACL (Access Control List).
8.6 Modèle de replication
Un modèle de réplication est prévu dans la norme LDAP, mais il n’est pas encore standardisé. La réplication est un élément important pour assurer une redondance qui reste le moyen privilégié par les administrateurs système pour se prémunir des pannes. Les différentes implémentations LDAP (Active Directory, OpenLDAP, ..) ont développé leurs systèmes de réplication.
À noter également que LDAP fournit un format d’échange standard nommé LDIF (LDAP Data Interchange Format) qui permet d’échanger/sauvegarder de l’information entre serveurs LDAP. Cependant celui-ci ne permet pas une réplication aisée.
8.7 LDAP vs SGBD
| LDAP | SGBD |
|---|---|
| Attribut multi-valeurs | / |
| Query LDAP | Query SQL |
| Modèle de données défini, mais extensible facilement | Définition du modèle par le dévelopeur, extensible mais difficile |
8.8 Active Directory
L’Active Directory permettra de gérer l’authentification des utilisateurs d’un ou plusieurs domaines, de gérer les droits des utilisateurs via des groupes de sécurité. Un Active Directory définira une forêt qui sera composée d’arbres (domaine parent avec des domaines enfants) et/ou de domaines. Les domaines seront, quant à eux, constitués d’unités d’organisation et enfin d’ordinateurs, de groupes et utilisateurs.
Dans un Active Directory, nous allons retrouver différents objets. Les plus importants sont les utilisateurs, les ordinateurs du domaine, les groupes de sécurité, les GPO (Voir GPO), les unités d’organisation.
Un serveur hébergeant un Active Directory est appelé contrôleur de domaine. Il est conseillé d’avoir au minimum 2 contrôleurs de domaine par Active Directory pour se prémunir des pannes.
8.8.1 Unité d’organisation
Une unité d’organisation est un regroupement d’objets de l’Active Directory. C’est un nœud dans l’arbre LDAP. Les unités d’organisation trouvent essentiellement leur utilité par le fait que des GPO puissent être définies à ce niveau.
Ne pas confondre les unités d’organisation et les groupes de sécurité. Des GPO ne peuvent pas être définies sur des groupes et des permissions ne peuvent pas être définies sur des unités d’organisations. Un objet (utilisateur) peut appartenir à plusieurs groupes, il ne pourra pas contre être placé que dans une seule unité d’organisation.
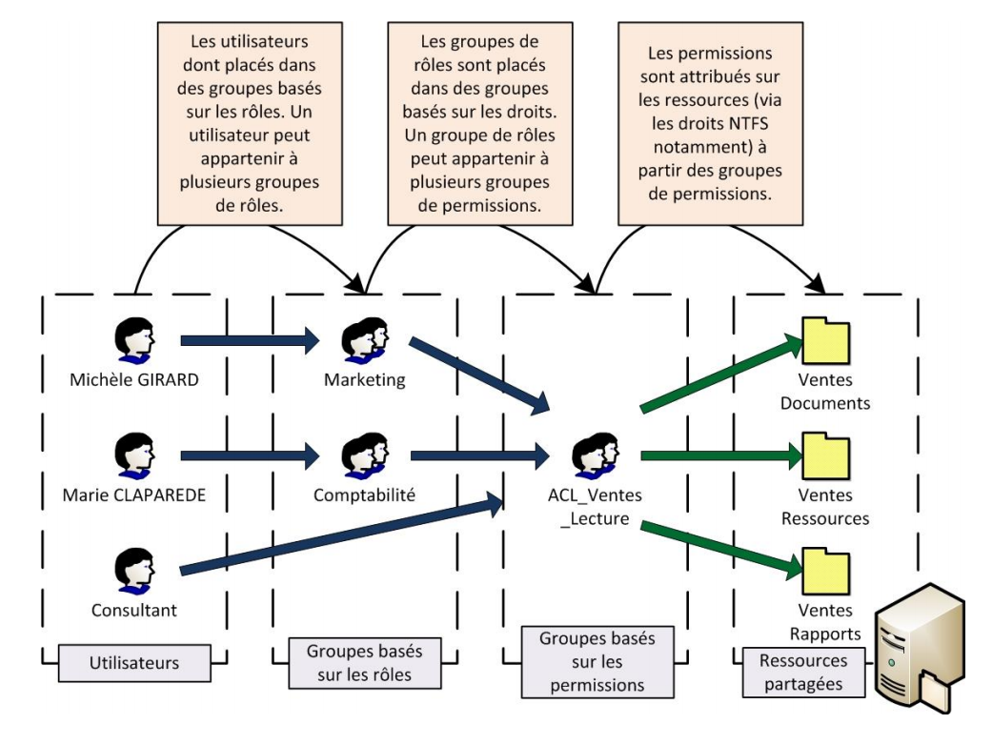
8.8.2 Groupes de sécurité
Microsoft propose une recommandation pour la gestion des droits et des groupes. Il s’agit de la recommandation AG(U)DLP.
Account → Global → (Universel) → Domain Local → Permission
schéma utile à connaître pour expliquer AG(U)DLP :
8.8.3 Permissions
8.8.3.1 Permissions NTFS
Microsoft utilise le système de fichiers NTFS et dès lors les permissions seront des permissions NTFS. Les permissions NTFS sont très riches (beaucoup de possibilités).
8.8.3.2 Permissions Partage réseau
Attention à ne pas confondre les permissions NTFS qui s’appliquent directement sur des fichiers et dossiers locaux (présents sur le système de fichiers) et les permissions de partage qui sont définies sur les partages réseau.
Lors de l’accès à un partage réseau, le système évalue tout d‘abord les permissions du partage réseau et ensuite les permissions NTFS (puisque tout partage réseau se retrouve toujours physiquement sur un système de fichiers).
8.9 GPO
Les GPO (Group Policy Object) permettent de définir des stratégies de sécurité et/ou de configurer des paramètres de manière centralisée pour un domaine ou une forêt. Par exemple, on peut imposer un proxy pour les clients, définir un fond d’écran, définir une politique de mot de passe (longueur, complexité …).
Les GPO, aussi appelées stratégie de groupe en français, permettent de déployer des stratégies/paramètres sur 2 types objets de l’Active Directory : les utilisateurs et les ordinateurs. Les GPO se créent le plus souvent sur des Organizational Unit.
Les GPO machines (configuration ordinateur) s’appliquent au démarrage de la machine. Les GPO utilisateurs (configuration utilisateur) s’appliquent à l’ouverture de session d’un utilisateur.
9 Gestion des données
9.1 Objectifs du chapitre
- Etablir un plan de sauvegarde des données
9.2 Base de données
9.2.2 Exemple PostgreSQL
Un moteur de base de données est constitué de plusieurs programmes. PostgreSQL est composé d’un programme superviseur (postmaster), du serveur exécutant les requêtes (postgres) et d’un client interactif (psql).
9.2.2.3 Sauvegarde PostgreSQL
Il est important de sauvegarder les bases de données. Voici les erreurs à ne pas commettre :
- Pas de sauvegarde
- Sauvegarde jamais testée
- Ne pas documenter sa sauvegarde (qui l’a fait/ quand, comment …)
- Sauvegarder sur le même disque
- Sauvegarder au même endroit (incendie ?)
- N’avoir qu’une sauvegarde très récente car elle contiendra également l’erreur
Les sauvegardes de type fichiers ou instantanés ne conviennent pas aux bases de données. Il est préférable d’utiliser l’outil fourni par le moteur de base de données. Dans le cas de PostgreSQL, nous avons pg_dump.
9.2.2.4 Performance PostgreSQL
Il est important de savoir que les limitations des bases de données se situent essentiellement du côté des composants sous-jacents (CPU, RAM, vitesse disque, capacité disque …).
La performance passe également par l’ajout d’index. Un index peut accélérer par 1000 000 une requête !
L’utilisation de LIMIT est également à envisager. Doit-on vraiment charger l’entièreté d’une table, les premiers résultats ne sont-ils pas suffisants ?
L’utilisation régulière de VACUUM pour supprimer définitivement les données expirées est à envisager, particulièrement sur les bases de données des développeurs qui créent et détruisent souvent leurs bases de données.
L’utilisation d’ANALYSE permet de collecter des statistiques en vue d’optimiser la base de données.
Un petit mot sur les ORM pour finir. Ceux-ci sont très utiles, mais l’optimisation s’avère souvent plus complexe à gérer vu que vous laissez l’ORM créer les requêtes SQL pour vous. En tant que développeur, posez-vous (ou à votre chef de projet) donc la question de la performance avant de vous décider.
9.2.2.5 Réplication PostgreSQL
Comme d’habitude, les administrateurs systèmes ou DBA vont vouloir se prémunir des pannes en installant de la redondance. Avec les bases de données, ceci peut se faire en activant la réplication. Ce mécanisme permet à 2 moteurs de base de données de partager des bases de données. Les données de ces bases de données se retrouvent alors répliquées/dupliquées au minimum sur 2 serveurs de bases de données.
La réplication la plus utilisée est celle dite du maître – esclave. Toutes les opérations sont faites sur le serveur maître et celui-ci envoie régulièrement au serveur esclave ses journaux de transactions. Ce dernier rejoue alors le journal de transactions sur sa base de données.
9.3 Sauvegardes
Un administrateur système sera en charge de la pérennité des données. Pour cette tâche, des sauvegardes ou backups seront nécessaires.
Bien sûr il est souvent impossible de tout sauvegarder, c’est pourquoi il faut définir une politique de sauvegarde qui répond aux questions suivantes.
9.3.2 Sur quel support sauvegarder ?
Les entreprises auront donc souvent recours à des NAS (Network Area Storage) ou SAN distants ou encore à un stockage dans le Cloud.
9.3.3 Quel type de sauvegarde, quelle fréquence ?
Il existe différents types de sauvegarde à savoir :
- complète : une copie complète des données est faite
- incrémentielle : une copie des modifications depuis la dernière sauvegarde (complète ou incrémentielle) est faite
- différentielle : une copie des modifications depuis la dernière sauvegarde complète est faite
- miroir : une seule sauvegarde complète.
- instantané/snapshot : pas vraiment une sauvegarde car difficile de restaurer un seul fichier
9.3.4 Conservation des données ?
La déduplication est un autre moyen mis en place par les entreprises. Ce mécanisme est souvent intégré au SAN.
Il est nécessaire de crypter ses backups pour éviter à une personne mal intentionnée de récupérer facilement les données de l’entreprise. L’utilisation grandissante du Cloud renforce également ce besoin.
9.3.6 La règle du 3-2-1
Il existe une règle fortement conseillée pour les sauvegardes de données. Il s’agit de la fameuse règle 3-2-1.
- 3 : conserver 3 copies des données (originale + 2 sauvegardes)
- 2 : conserver les données sur 2 supports différents
- 1 : conserver 1 copie de sauvegarde dans un lieu différent (des 2 autres copies)
9.4 Quotas
Les quotas permettent donc de régler ce problème en imposant une limite aux utilisateurs. Le mécanisme de quotas propose une limite soft et une limite hard. Quand un utilisateur dépasse sa limite soft, il reçoit un avertissement lui indiquant qu’il peut continuer à travailler pour une période de grâce définie par l’administrateur. Une fois cette période grâce écoulée, il est bloqué s’il n’est pas redescendu en dessous de la limite soft.
10 Virtualisation
10.1 Objectifs du chapitre
- Comprendre la virtualisation, les différents types de virtualisation
10.2 Avantages de la virtualisation
La virtualisation consiste en l’abstraction d’un élément du monde réel en le rendant virtuel. Ceci dans l’objectif de rendre l’élément plus facilement :
- Configurable
- Transportable
- Optimisé (meilleure allocation des ressources)
- Disponible (facilité de déploiement)
- Sécurisé (isolation)
10.4 Inconvénients de la virtualisation
L’inconvénient majeur de la virtualisation est l’ajout d’une couche de virtualisation entre le système physique et le composant virtualisé. Ceci permet d’obtenir les avantages cités ci-dessus, mais dégrade les performances.
10.5 Hyperviseurs
Un hyperviseur est un logiciel de virtualisation permettant à plusieurs machines virtuelles de fonctionner simultanément sur un même système physique.
- Hyperviseur type 1 / natif / bare-metal
- Hyperviseur type 2 / hosted
Un hyperviseur de type 1 sera utilisé dans le cadre de la virtualisation de serveurs.
serveurs privés virtuel (VPS)
Ce que vous connaissez le plus est certainement les hyperviseurs de type 2. Ces hyperviseurs s’installent dans un système d’exploitation comme un logiciel classique. On peut citer VirtualBox.
10.6 Virtualisation du stockage
La virtualisation du stockage consiste donc en la création d’une baie de stockage (ensemble de disques physiques) qui sera présentée en un ou plusieurs ensembles logiques et dynamiques. On parle de LUN (Logical Unit Number). Une LUN est donc un espace de stockage logique et dynamique.
Un SAN est donc une baie de stockage avec des LUN accessibles via le réseau.
10.8 Le cas VirtualBox
La possibilité de réaliser un instantané/snapshot dans les solutions de virtualisation est un énorme avantage. Ceci permet de revenir facilement à un état antérieur en cas de souci. Il est donc vivement conseillé de réaliser un instantané avant toute modification importante d’un système.
11 Conteneurs (Docker)
11.1 Objectifs du chapitre
- Comprendre les architectures à base de conteneurs
- Savoir créer un Dockerfile
- Déployer des applications via Docker, docker-compose
11.2 Docker
11.2.1 Introduction
Docker est une solution d’architecture à base de conteneurs. Les architectures à base de conteneurs sont une évolution avantageuse de la virtualisation.
Docker n’est donc pas un logiciel de virtualisation, mais un isolateur.
Les cgroups (Control Groups) permettent de fixer/limiter les ressources (CPU, Réseau, disque, nombre de processus) allouées à un conteneur ou un ensemble de conteneurs.
Les namespaces permettent d’isoler des ressources. Ainsi un conteneur ou ensemble de conteneurs ne voient que les ressources de son namespace.
Les conteneurs sont proches des machines virtuelles, mais présentent un avantage important. Alors que la virtualisation consiste à exécuter de nombreux systèmes d’exploitation sur un seul et même système, les containers se partagent le même noyau de système d’exploitation et isolent les processus de l’application du reste du système.
Les architectures à base de conteneurs sont très utilisées car elles permettent facilement des mises à l’échelle (scaling).
En effet, on peut facilement augmenter le nombre de conteneurs lorsqu’une application est fortement demandée. On appelle cela la mise à échelle horizontale (horizontal scaling). On peut également augmenter les ressources des conteneurs via les cgroups. On appelle cela la mise à échelle verticale (vertical scaling). On peut bien évidemment combiner les 2 mises à l’échelle. Quand la demande est moins forte, on peut réduire le nombre de conteneurs et/ou les ressources et par conséquent épargner de l’argent.
11.2.2 Docker vs Virtualisation
La grosse différence entre Docker et les systèmes de virtualisation classiques se situe au niveau de l’interaction avec le système d’exploitation hôte.
- Docker partagera/utilisera le même noyau (Linux) pour tous les conteneurs.
- Chaque VM géré par un hyperviseur aura son propre OS
11.2.4 Utilisation de Docker
Pour déployer une application via Docker, il y a donc 3 étapes essentielles :
- Création d’un Dockerfile (recette de cuisine de l’application à déployer)
- Créer l’image Docker (
docker build -t <imagename> <pathToDockerfile>) - Créer un conteneur à partir de l’image créée (
docker run -d -p 9000:80 --name <containername> <imagename>)
Les points suivants de ce syllabus détailleront les différents éléments de ce schéma à savoir :
- Le Dockerfile et ses principales instructions
- Les commandes de gestion des images Docker
- Les commandes de gestion des conteneurs Docker
- Les Registry et DockerHub
11.2.4.1 Dockerfile et instructions principales
La conteneurisation d’une application commence par la création d’un dossier contenant tout ce qui est nécessaire à l’application. Ce dossier doit contenir au minimum :
- le code de l’application
- un fichier Dockerfile
11.2.4.4 Registry et DockerHub
Le DockerHub est l’endroit où vous devez rechercher votre image de base !
11.2.5 Points importants
11.2.5.1 Couches
A noter que Docker utilise un système de couche (layer) à des fins d’optimisation des build d’images. Une couche est une image intermédiaire.
Pour chaque ligne du Dockerfile, Docker crée une couche. Une image Docker est donc un empilement de couches c’est-à-dire d’images intermédiaires. Ainsi nul besoin pour Docker de tout refaire à chaque build, il va réutiliser les couches qui n’ont pas changé.
11.2.5.2 RUN vs CMD
Ces 2 instructions ne sont pas similaires. RUN crée une nouvelle couche (image intermédiaire) en incluant le résultat de la commande qu’on lui transmet. Cette instruction agit donc au niveau de l’image (docker build).
CMD exécute une commande à chaque démarrage d’un conteneur. Cette instruction agit donc au niveau du conteneur. Cette instruction est souvent nécessaire pour le démarrage de services (Apache, nodeJS, …).
11.3 docker compose
Docker est prévu pour faire fonctionner des architectures microservices. Dans ce type d’architecture, on crée un conteneur par service.
Ceci est bien beau mais :
- Comment gère-t-on la communication entre les différents conteneurs ? Le conteneur application devra vraisemblablement communiquer avec le conteneur db.
- Comment rend-on des données persistantes ? Un conteneur est stateless mais les données d’un conteneur db devront être persistées.
docker compose permet également facilement la création de volumes. Ceci permet d’effectuer la persistance de données en dehors d’un conteneur.
11.3.4 Directives intéressantes
La directive «build» permet de construire une image Docker à partir d’un Dockerfile.
La directive «ports» permet d’effectuer la redirection de ports (port forwarding) entre la machine hôte et le conteneur.
La directive «volumes» permet de lier un répertoire de la machine hôte au conteneur. Les volumes ne sont pas détruits par défaut lors de la destruction du conteneur. C’est donc via ce biais que les données persistantes des conteneurs sont gérées.
11.3.5 Réseau
Les noms des services (conteneurs) deviennent des noms réseaux.
11.4 The Twelve Factor App
La conception de Docker s’est inspirée de la méthodologie des 12 facteurs, une méthodologie pour créer des applications SaaS Modèles de service. Voici un lien vers cette méthodologie https://12factor.net/fr/. Voyons comment Docker applique celle-ci.
Retenez cinq facteurs avec leurs exemples Docker.
- Code de base : La notion d’image en Docker permet clairement de déployer plusieurs fois un même code ou des versions différentes de ce même code.
- Dépendances : Le Dockerfile rend explicite les dépendances.
- Configuration : Il est possible de passer des variables d’environnement à un conteneur. Cependant un orchestrateur (k8s, voir paragraphe suivant) pourra le faire de manière plus élégante.
- Services externes : Les ressources peuvent être découvertes via leur nom. Cependant un orchestrateur (k8s) pourra le faire de manière plus élégante.
- Build, Release, Run : docker build, docker run
- Processus : Docker est principalement stateless. Les volumes existent mais il sera plus élégant de gérer cela avec un orchestrateur. Il n’est pas rassurant de savoir ces volumes stockés sur une machine hôte qui peut faillir.
- Association de ports : docker run -p 8080:80
- Concurrence : Le côté stateless des conteneurs permet facilement de créer plusieurs conteneurs pour faire face à la montée en charge.
- Jetable: Avec Docker, on crée, on déploie et supprime facilement une application.
- Parité Dev / Prod : la même image peut être lancée en prod ou en dev.
- Logs : Par défaut tous les logs Docker sont envoyés vers stdout (d’où le fait que Docker oblige les applications à tourner en avant-plan).
- Processus d’administration : Il est très facile de se connecter et d’interagir avec un conteneur (docker exec -it).
11.5 Kubernetes (K8s)
11.5.1 Introduction
Kubernetes est un orchestrateur de conteneurs.
11.5.2 Utilité
Kubernetes permet d’appréhender les défis liés à la gestion des conteneurs notamment :
- l’équilibrage de charge entre plusieurs conteneurs (load balancing)
- la gestion des différents stockages pour les conteneurs (volumes). Ceux-ci peuvent être locaux, dans le Cloud, …
- la gestion et l’allocation des ressources aux conteneurs de manière dynamique
- la gestion de l’état de santé des conteneurs
- la gestion des informations de configuration et des secrets (clé SSH, password, .. )
11.5.3 Vue générale et concepts k8s
Kubernetes est composé d’un nœud maître permettant la gestion du cluster k8s. Un cluster est un ensemble de machines physiques ou virtuelles. Chaque machine du cluster est appelée un “worker node” et contiennent une solution de déploiement de conteneurs (Docker par ex.).
Chaque “worker node” héberge un pod. Un pod est l’unité de déploiement d’une application dans k8s. Il s’agit d’un ou plusieurs conteneurs. Dans la pratique, le plus souvent un pod == un conteneur/un processus.
Un label est un couple “clé:valeur” que l’on peut attacher à un objet, notamment un pod. Les selectors permettent de sélectionner un objet k8s suivant son label
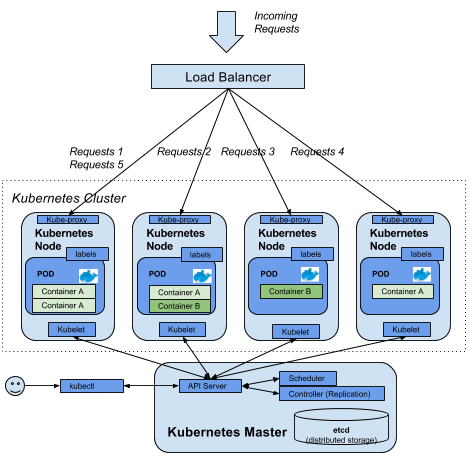
Un fichier deployment.yml permet de définir comment un Pod sera déployé. Ce fichier contient une instruction “replica” qui indiquera à K8s combien d’instances de ce Pod il devra lancer/maintenir.
Un fichier services.yml permet de définir et gérer le réseau à l’intérieur du cluster. Vu que les pods peuvent être créés, détruits et recréés, il est nécessaire qu’un service puisse cibler les pods encore actifs à un moment t.
Ingress est un load balancer qui permet de faire communiquer le monde extérieur avec le cluster k8s.
Les Persistent Volume Claim (PVC) permettent de persister des données. Cela va beaucoup plus loin que l’utilisation de simples volumes (PV). Il s’agit d’une demande d’espace adressée à k8s. Celui-ci attribuera alors au pod un stockage suivant sa demande. A noter aussi que l’intérêt de k8s par rapport au stockage est de pouvoir utiliser des stockages variés (Amazon, Azure, Local, …).
12 DevOps
12.1 Objectifs du chapitre
- Consolider les notions DevOps
- Déployer des configurations via Ansible
- Déployer une pipeline via Jenkins
12.2 Introduction
Le déploiement d’une application faisant maintenant partie du produit ainsi que les mises à jour en continu, il est donc nécessaire d’avoir une infrastructure avec le concours des opérationnels pour mener à bien ce nouveau mode de développement logiciel.
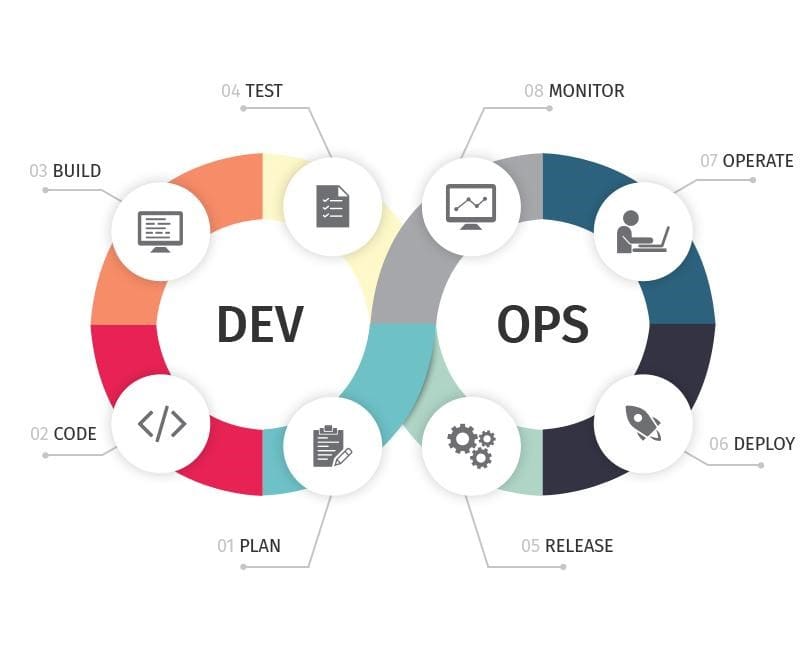
Schéma à connaître
12.2.1 Pipeline de développement
L’approche DevOps mise également sur l’automatisation via des outils. On parlera souvent de pipeline de développement. Il s’agit d’une chaîne de production logicielle la plus automatisée possible jusqu’au client. Celle_ci se divise généralement en une partie CI (Continuous Integration) qui s’occupe de tester l’application et une partie CD (Continuous Deployment) qui s’occupe de déployer l’application pour les clients.
Sans surprise, les pipelines utiliseront les éléments vus dans les chapitres précédents surtout les conteneurs, les orchestrateurs, le Cloud et les outils de configurations.
DevOps du côté développeurs :
DevOps va privilégier une architecture microservice, car celle-ci permet un meilleur contrôle et une montée en charge facilitée.
DevOps du coté des sysadmins : Les outils utilisés par les sysadmins dans ce cadre sont des outils de gestion de configuration (Chef, Puppet, Ansible, ..), des outils de gestion et utilisation des conteneurs (Docker, K8s).
12.3 Pipeline - Jenkins
Jenkins est un outil open source écrit en Java permettant notamment la création de pipelines. Il s’intègre parfaitement avec d’autres outils comme Docker , Github, … .
12.4 Ansible
12.4.1 Introduction
Pour les administrateurs systèmes, il est nécessaire de disposer d’outils pour automatiser les tâches d’installations et de configurations. En effet, les administrateurs systèmes doivent s’occuper d’un parc de machines et il est donc insensé de configurer toutes ses machines à la main.
Pour ce faire, il existe différents outils permettant d’automatiser les installations et configurations. Nous pouvons citer Puppet, Chef et Ansible. Nous verrons Ansible en labos car il peut également se révéler utile pour un développeur.
Ansible a défini son propre vocabulaire. On parle de contrôleur qui est est la machine qui exécute Ansible en tant que tel et de cibles qui sont les machines (hosts) qu’Ansible configure. Les cibles sont définies dans l’inventaire d’Ansible, simple fichier reprenant des noms de machines ou IP de machines. A noter que le contrôleur et la cible peuvent être la même machine. Dans ce cas, cela signifie que nous automatisons alors simplement un ensemble de tâches pour une seule machine. Nous procéderons de cette manière durant les labos. Vous verrez que l’on précisera toujours dans notre fichier Ansible localhost comme cible !
12.4.8 Rôle Ansible
Ansible permet de séparer un playbook dans plusieurs fichiers. On appelle cela un rôle Ansible. Un rôle Ansible est un répertoire contenant l’arborescence suivante :
- defaults : valeurs par défaut des variables
- files : fichiers statiques à déployer
- handlers : tâches pouvant être appelées par notification
- tasks : tâches à effectuer
- templates: modèles de fichier de configuration
- tests : tests pour le rôle
- vars : variables spécifiques du playbook
- README.md : description générale du rôle
12.5 Observabilité
12.5.1 Introduction
Sur un serveur isolé, on peut facilement consulter les logs, regarder certaines métriques pour établir un bilan de santé du serveur ou de notre applciation. Cependant dans une infrastructure avec plusieurs serveurs, ayant eux-mêmes des milliers de conteneurs, il est nécessaire de s’outiller et de faire remonter les informations sur celle-ci vers un endroit centralisé.
Composantes principales :
-
Logs - Enregistrements textuels des événements système ou applicatifs. - Utiles pour le debugging et les audits.
-
Métriques - Données numériques sur les performances (CPU, mémoire, latence, etc.). - Utilisées pour les alertes et les tableaux de bord.
-
Traces distribuées - Suivi d’une requête à travers plusieurs services. - Essentiel pour les architectures microservices.
-
Evénements - Actions ou changements d’état détectés dans le système. - Peuvent déclencher des alertes ou des automatisations.
12.5.2 Outils de surveillance
| Outil | Type | Description courte |
|---|---|---|
| Prometheus | Monitoring/metrics | Collecte de métriques, intégration avec Grafana |
| Grafana | Visualisation | Tableaux de bord pour visualiser les informations remontées |
| Loki | Logs/Analyse | Collecte et indexation centralisée de logs, intégré à Grafana |
| Alloy | Collecte/Agent | Agent unifié pour collecter logs, métriques et traces, compatible Grafana |
12.5.3 Architecture de surveillance - Logs
| Composant | Rôle | Fonction principal | Exemple d’outil |
|---|---|---|---|
| Agent | Collecte | Capture les logs, métriques et traces depuis les sources | Grafana Alloy, Fluentd |
| Répartiteur | Distribution | Valide et répartit les logs vers les composants de traitement | Loki Distributor |
| Stockage temporaire | Indexation et buffer | Stocke les logs en mémoire, les indexe avant archivage | Loki Ingester |
| Évaluateur de règles | Analyse et alertes | Applique des règles pour générer des alertes ou transformer les données | Loki Ruler |
| Moteur de requêtes | Interrogation | Permet la recherche et l’analyse des logs | Loki Querier |
| Interface utilisateur | Visualisation | Affiche les logs, métriques, traces et dashboards interactifs | Grafana |
13 Cloud (Terraform notamment)
13.1 Objectifs du chapitre
- Connaître les modèles de service Cloud
- Architecture Multi-tenant et Cloud
- Déployer des services PaaS avec Terraform
13.2 Introduction Cloud
Le Cloud est une abstraction de l’infrastructure.
13.4 Modèles de service
13.4.1 Infrastructure as a Service (IaaS)
IaaS : Déploiement d’une infrastructure via les outils du fournisseur Cloud. L’utilisateur peut paramétrer le réseau, les serveurs, … . Ex: Amazon EC2, Azure VM, …
Terraform est certainement l’outil le plus utilisé pour déployer de l’IaaS. Il permet de créer des VM et d’autres éléments d’infrastructure sur AWS, Azure, … . Cet outil est décrit dans la section suivante.
13.4.2 Platform as a Service (PaaS)
PaaS : Déploiement d’une plateforme via les outils du fournisseur Cloud. L’utilisateur peut paramétrer la plateforme mais celui ci n’a aucun accès, vue sur l’infrastructure. Ceci est un des modèles de service Cloud les plus employés par les développeurs. Ex: Heroku, AWS Elastic Beanstalk, Cloud Foundry, …
13.4.3 Function as a Service (FaaS)
FaaS: Déploiement d’une fonction dans le Cloud. Ici l’utilisateur ne paramètre rien. Il choisit son langage et écrit son code. Aucun accès, vue sur l’infrastructure, paramétrage. Ceci est un des modèles de service Cloud les plus employés par les développeurs. Ex: fonctions lambda AWS,…
13.4.4 Software as a Service (SaaS)
SaaS: Accès à une application via Internet. Aucun accès, vue sur l’infrastructure, paramétrage par l’utilisateur limité. Ex: Gmail, Office365,…
13.5 Architecture Multi-tenant et Cloud
13.5.1 Introduction
Dans une architecture multi-tenant, une même instance d’une application logicielle est utilisée par plusieurs clients, ces derniers étant des « tenants ».
Le modèle multi-tenant peut s’avérer économique, étant donné que les coûts liés au développement et à la maintenance des logiciels sont partagés.
| Architecture | Instance App | Base de données | Isolation | Coût |
|---|---|---|---|---|
| Single-Tenant | 1 par client | 1 par client | Très forte 🔒 | Élevé 💸 |
| Multi-Tenant | 1 partagée | 1 partagée ou multi-DB | Moyenne à forte 🧩 | Faible à moyen 💰 |
| Multi-DB (option) | Variable | 1 par client | Forte 🔐 | Moyen à élevé 💵 |
Les modèles de service SaaS présentes dans le Cloud proposent souvent les approches multi-tenant et single-tenant.
13.6 Terraform / OpenTofu
13.6.1 Introduction
Terraform est un outil permettant de déployer des ressources dans le Cloud. En clair, il permet d’automatiser la création de ressources (VM, image docker, …) en local ou dans le Cloud. Il dispose de nombreux connecteurs (providers) permettant de créer des ressources aussi bien dans AWS (Amazon), Azure, en local, … Ce dernier point le rend particulièrement intéressant au sein des entreprises.
Ces noms de référence doivent être en minuscules et sans caractères spéciaux (pas d’underscore !).
13.6.4.4 Déploiement LocalStack
Pour rappel, LocalStack permet d’émuler des services AWS en local. Nous n’utiliserons que quelques services (les principaux) d’AWS à savoir :
- s3 : Ce service est aussi appelée Bucket. Il s’agit d’un service de stockage de fichiers en tout genre. Ceci permet notamment de stocker des fichiers images pour une application ou encore de déployer un site Web statique.
- lambda : Il s’agit d’un service FaaS. Ceci permet de déployer une fonction (morceau de code JS, Python, ….) directement dans le Cloud.
- dynamodb : Il s’agit d’un moteur de base de données NoSQL de type clé-valeur.
- ec2 : Il s’agit d’un service IaaS. Ceci permet de déployer des “instances EC2” c’est-à-dire des machines virtuelles.